Diffusion Models
Introduction

photography, night, modern building, the image is blurring to the right. Image created with Midjourney by jcmm.art
Introduction
Diffusion Models are a class of generative models that have gained significant popularity in recent years.
They are used to generate data similar to the data on which they are trained.
The goal of diffusion models is to learn a diffusion process that generates the probability distribution of a given dataset.
Fundamentally, Diffusion Models work by destroying training data through the successive addition of Gaussian noise, and then learning to recover the data by reversing this noising process.
Diffusion models were introduced in 2015 as a method to learn a model that can sample from a highly complex probability distribution.
They used techniques from non-equilibrium thermodynamics, especially diffusion.
Consider, for example, how one might model the distribution of all naturally-occurring photos. Each image is a point in the space of all images, and the distribution of naturally-occurring photos is a “cloud” in space, which, by repeatedly adding noise to the images, diffuses out to the rest of the image space, until the cloud becomes all but indistinguishable from a gaussian distribution.
They have shown incredible capabilities as generative models and power the current state-of-the-art models on text-conditioned image generation such as Imagen by Google, DALL-E by OpenAI, Stable Diffusion by Stability.ai and Midjourney by Midjourney Inc.
Diffusion Model mainly consists of three major components:
The Forward process, the Reverse process, and the Sampling procedure.

Forward Process:
The forward process in diffusion models is a Markov chain that gradually adds noise to input data until white noise is obtained. This process is responsible for adding noise. It’s like diffusing a cloud of points representing the data in high-dimensional space until it becomes indistinguishable from a Gaussian distribution.
Reverse Process:
The reverse process aims to reverse the forward process step by step, removing the noise to recover the original data. This process is responsible for training networks. It’s like condensing the diffused cloud back into its original shape.
Sampling Procedure:
The sampling procedure generates a new sample using random noise as input. This process is responsible for generating samples. It’s like picking a point from the cloud and following the reverse process to get a sample from the original distribution.
Video created with Midjourney by jcmm.art
Conditional Image Generation: Guided Diffusion
A crucial aspect of image generation is conditioning the sampling process to manipulate the generated samples. Here, this is also referred to as guided diffusion.
There have even been methods that incorporate image embeddings into the diffusion in order to “guide” the generation.
Word embeddings
Word embeddings give us a way to use an efficient, dense representation in which similar words have a similar encoding. Importantly, you do not have to specify this encoding by hand.
An embedding is a dense vector of floating point values (the length of the vector is a parameter you specify).
Instead of specifying the values for the embedding manually, they are trainable parameters (weights learned by the model during training, in the same way a model learns weights for a dense layer).
It is common to see word embeddings that are 8-dimensional (for small datasets), up to 1024-dimensions when working with large datasets. A higher dimensional embedding can capture fine-grained relationships between words, but takes more data to learn.
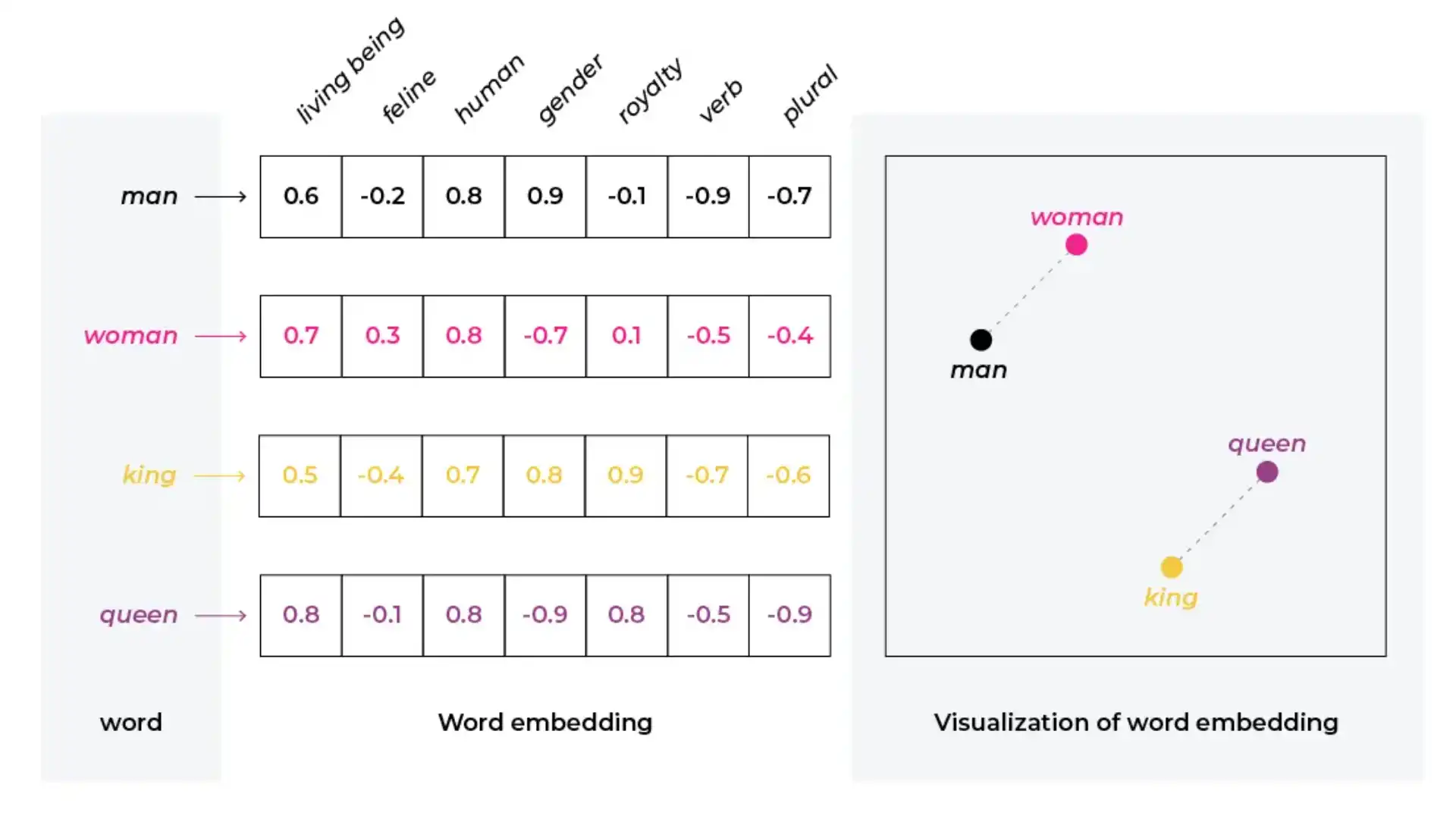
image by Arize.com