Stable Diffusion
Introduction

image generated with Stable Diffusion (LookX.ai) by jcmm.art
Stable Diffusion is a groundbreaking development in the field of artificial intelligence (AI), specifically in the realm of image generation.
This text-to-image diffusion model has the capability to generate photo-realistic images from any text input.
It’s a significant advancement in image generation capabilities, offering enhanced image composition and face generation that results in stunning visuals and realistic aesthetics.
The model was developed by researchers from the Machine Vision and Learning group at LMU Munich, also known as CompVis. The model checkpoints were publicly released at the end of August 2022 by a collaboration of Stability AI, CompVis, and Runway with support from EleutherAI and LAION1.

image generated with Stable Diffusion (getimg.ai) by jcmm.art
Stable Diffusion is not just an open-source machine learning model that can generate images from text, but it can also modify images based on text or fill in details on low-resolution or low-detail images.
The underlying dataset for Stable Diffusion was the 2b English language label subset of LAION 5b, a publicly accessible database in which 5 billion image-text pairs were classified.
Stable Diffusion was trained on 2.3 billion image-text pairs in English. The other 100+ languages add up to 2.2 billion such pairs.
Images created through Stable Diffusion Online are fully open source, explicitly falling under the CC0 1.0 Universal Public Domain Dedication. This means that anyone can use these images for any purpose without any restrictions.
The latest version is Stable Diffusion XL 1.0 and is hosted on the Hugginface.co and GitHub.com servers.
Unfortunately, installing SDXL on your PC requires a powerful graphics card and other computer specifications, such as:
- A minimum of 8 Gb of VRAM so that you don’t have to wait forever for the generation of images (recommended 12GB or 16GB of VRAM).
- Windows 10 or a more recent version.
- You’ll also want to make sure you have 16 GB of RAM in the PC system to avoid any instability.
- It also requires the installation of a number of utilities and programs such as Python (latest version), Git, a Web-UI (the most widespread are Automatic1111, NMKD and Comfy UI) and a proper configuration of your computer.
And of course you have to update every time a new version of one of the installed components is released.
Because of this, websites have proliferated where you have access to the latest models and even to fine-tuned models by users or by the website itself.
To name a few: DreamStudio and Clipdrop (from Stability.ai), LookX.ai, Getimg.ai, Replicate.com, Civitai.com, Leonardo.ai, Magai.co, …

image by stability.ai
Versions.
In just over a year (since June 2022) Stability.ai has released 5 versions improving both the resolution of the images and the fidelity to the prompts.
Version 1.4 in June 2022. Images resolution of 512×512 px.
Version 1.5 on August 22, 2022. Images up to 512×512 px. Higher level of realism.
Version 2.0 in November 2022. Images up to 512×512 px. Includes an Upscaler model that increases image resolution to 2048×2048.
Version 2.1 an update on December 1, 2022. Images up to 768x768px.
Stable Diffusion XL 1.0 on August 2023. Image resolution of 1024×1024 px. With the Upscaler model we can obtain images with a resolution of 4096×4096 px.
The addition of more pixels and visual information allows Stable Diffusion XL to produce imagery with a new level of hyperrealism and photo-accuracy, especially for scenes with lots of visual details and complications.
Compared to previous versions of Stable Diffusion, SDXL’s improved neural network architecture and training data enable photorealistic visual synthesis with unprecedented quality and precision.
Example images show sharply defined details, correct lighting and shadows, and realistic compositions.
It also shows improved capabilities for producing legible text within images.

image generated with Stable Diffusion (Getimg.ai) by jcmm.art

image generated with Stable Diffusion (Getimg.ai) by jcmm.art

image generated with Stable Diffusion (Getimg.ai) by jcmm.art
ControlNet

image generated with Stable Diffusion (LookX.ai) by jcmm.art
Stable Diffusion has 2 features that distinguishes it from other AI models such as Midjourney and Dalle:
1. It allows you to train the model with your own images.
2. Development by the software community allows improvement of the model through fine-tuning or add-ons that provide new features to the original model.
One of the most important, if not the most important, is the ControNet neural network.
image generated with Stable Diffusion (getimg.ai) by jcmm.art
ControlNet is a neural network that controls image generation in Stable Diffusion by adding extra conditions.
Details can be found in the article Adding Conditional Control to Text-to-Image Diffusion Models by Lvmin Zhang and coworkers(Lvmin Zhang, Anyi Rao, Maneesh Agrawala) 10 Feb 2023.
The most basic form of using Stable Diffusion models is text-to-image. It uses text prompts as the conditioning to steer image generation so that you generate images that match the text prompt.
ControlNet takes an image as additional input to the text prompt. This extra conditioning can take many forms.
The ControlNet models most suitable for architectural images are:
Lineart (standard, realistic, coarse), Canny, mlsd, Depth, Scribble, Hard edges, Soft Edges, Straight lines.
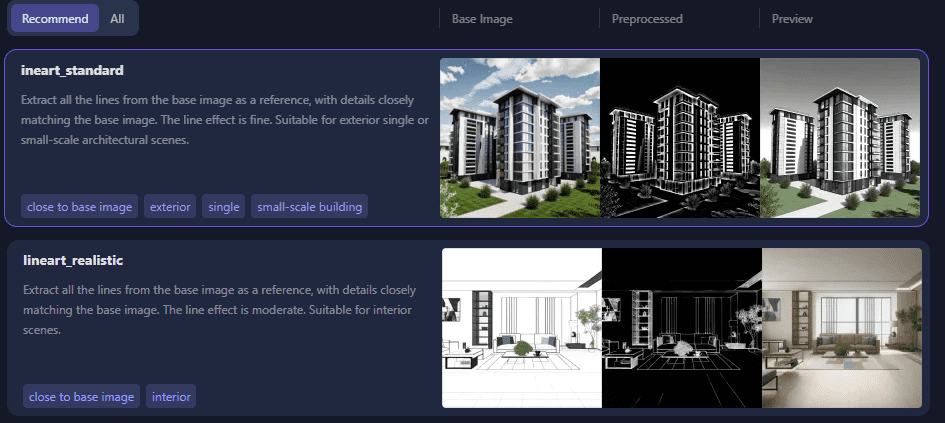
image from lookX.ai

image from lookX.ai
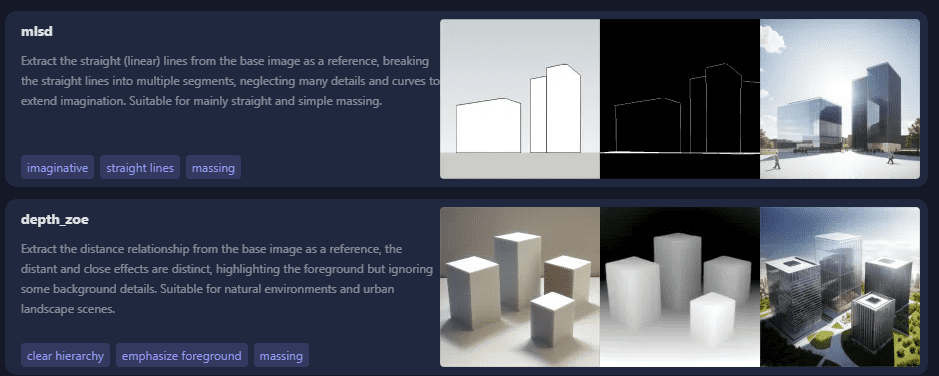
image from lookX.ai
Let’s go now to the practical part. We will use the infrastructure of two websites.
Both have access to the latest Stable Diffusion models and several ControlNET models.
It has a simpler interface to use and is more adapted to the generation of architectural images. However it has no utilities for AI image editing.
It was founded a few months ago by Tim Fu, an architect who worked as director of new technologies at Zaha Hadid.
It is not specialized in any field. But it is more versatile since all image generation parameters can be controlled.
It also has powerful utilities for editing the generated images.